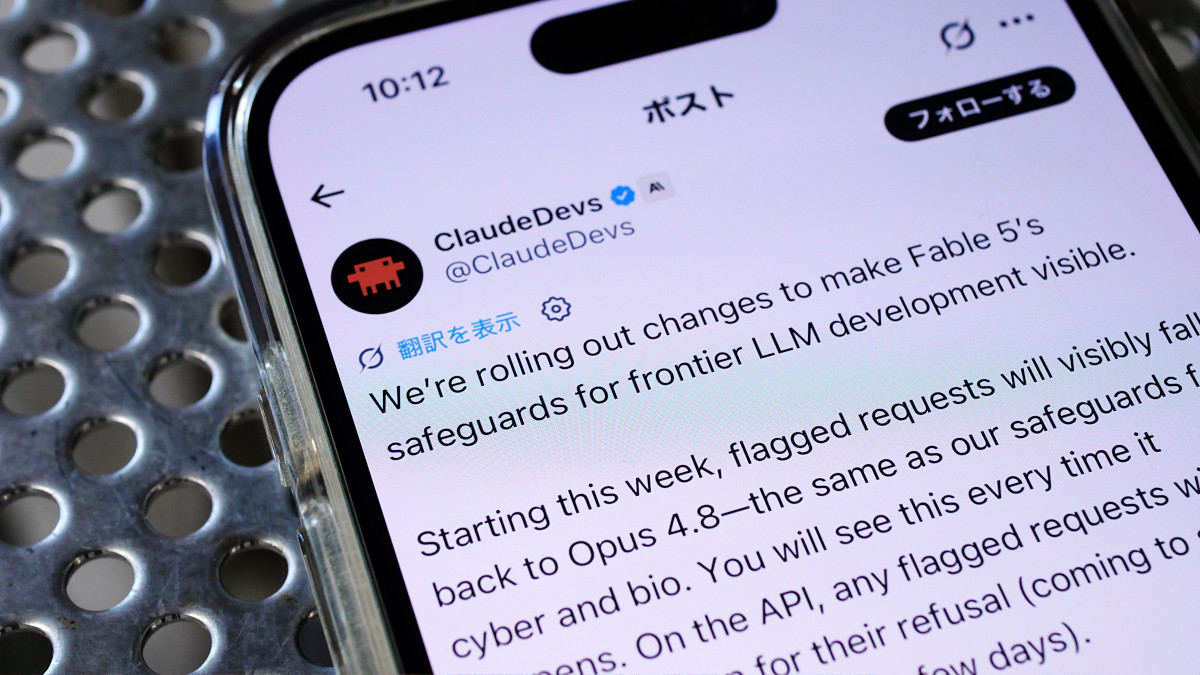
「Claude Fable 5のこっそりナーフ」についてAnthropicが公式声明を発表、AI研究用途でのモデル弱体化を改善へ
AnthropicがAIモデル「Claude Fable 5」の研究用途での性能弱体化について公式声明を発表しました。
AI&Tech、もう追いかけなくていい。
30秒で読めるニュースダイジェスト
AnthropicがAIモデル「Claude Fable 5」の研究用途での性能弱体化について公式声明を発表しました。

ジェフ・ベゾスが支援するプロメテウスが、物理世界向けの「汎用人工エンジニア」開発のため120億ドルを調…
.jpg)
Appleのカメラ責任者が、AIがユーザーに超能力を与える可能性について言及しました。
PreplyがOpenAIを活用し、AI生成のレッスン要約と個別フィードバックを提供開始しました。

SpaceXのIPOに関する初期分析で、意図せず投資家になっている可能性が指摘されました。

Microsoftが、AIエージェントのスキルを自動で最適化するオープンソースフレームワーク「SkillOpt」を公開…

MediaTekの株価が過去最高の四半期を記録し、AIチップへの転換が投資家の期待を集めています。

ロサンゼルスの大規模火災容疑者が、ChatGPTに燃える都市の画像生成を繰り返し要求し、拒否されたことが裁…

XiaomiがオープンソースのAIコーディングアシスタント「MiMo Code」を公開し、200ステップ以上の超長期タ…

サッカーのワールドカップでテクノロジー活用が進み、正確な判定やファンサービスを支えています。

パナソニックの43型4Kテレビ「VIERA W90A」がAmazonで47%オフの8万円台で販売中です。

AI需要の急増により、データセンター建設で電力供給の遅れが発生しているとガートナーが指摘しました。