
xAI共同創設者バブシュキン氏、パーソナライズAIの新スタートアップを発表
xAIの共同創設者であるイゴール・バブシュキン氏が、パーソナライズAIに特化した新スタートアップを立ち上…
AI&Tech、もう追いかけなくていい。
30秒で読めるニュースダイジェスト
xAIの共同創設者であるイゴール・バブシュキン氏が、パーソナライズAIに特化した新スタートアップを立ち上…

米国のサイバーセキュリティ・インフラセキュリティ庁(CISA)が、AIによる脅威の増大を受け、政府機関に…
オラクルが発表した第4四半期決算が市場予想を上回り、好調と評価されました。

日本のロボットソフトウェア開発企業Mujinが、2030年までの株式公開を目指し資金調達を進めています。

アマゾンがAI分野への大規模な投資を継続するため、複数の銀行から総額175億ドル(約2.7兆円)を借り入れ…

オラクルは予想を上回る設備投資を発表し、AIインフラ事業の収益性への懸念が高まりました。

投資家がAIインフラ構築関連のデータセンター債券に対し、より慎重な姿勢を見せている。
S&P 500企業の四半期収益がAI投資により大幅に成長しました。
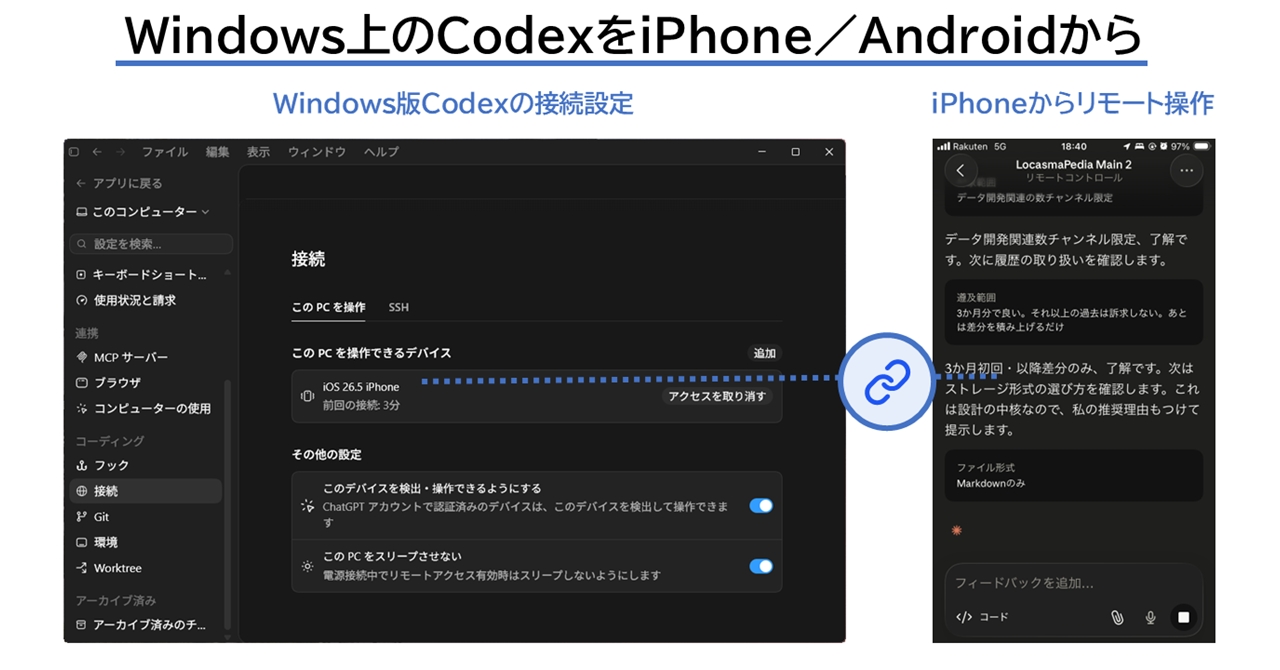
OpenAIのCodexアプリがスマホからWindows上の開発作業を操作可能になりました。

OpenAIは、中国関連のアカウントが米国でのデータセンター建設に対する地元住民の反対を煽動していると発…
Oracle Cloudユーザーが既存の契約コミットメントを利用してOpenAIのモデルとCodexにアクセスできるように…

SpaceXが3つの主要格付け機関から投資適格級の格付けを取得したと投資家に伝達しました。