
人間からのフィードバックによる強化学習(RLHF)の解説
RLHFは、人間がAIモデルの出力を評価し、そのフィードバックを基にモデルを改善する手法です。
AI&Tech、もう追いかけなくていい。
30秒で読めるニュースダイジェスト
RLHFは、人間がAIモデルの出力を評価し、そのフィードバックを基にモデルを改善する手法です。

Hugging FaceがElixirコミュニティ向けに機械学習ライブラリをリリースしました。
OpenAIのスーパーコンピューティングチームのエンジニア、クリスチャン・ギブソン氏がバックエンドシステ…

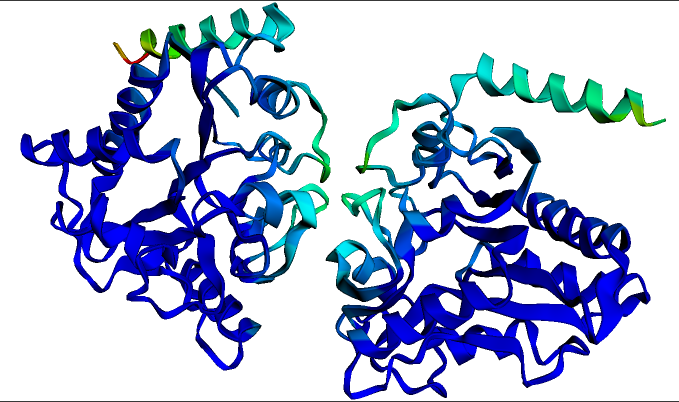
Hugging Faceがタンパク質研究における深層学習の活用方法を解説しました。

Apple Silicon搭載MacでStable DiffusionをCore MLに最適化し、高速な画像生成を実現しました。

Hugging FaceがTransformersモデルを用いた確率的時系列予測ライブラリを発表しました。
OpenAIが対話形式でユーザーとやり取りするAIモデル「ChatGPT」を発表しました。
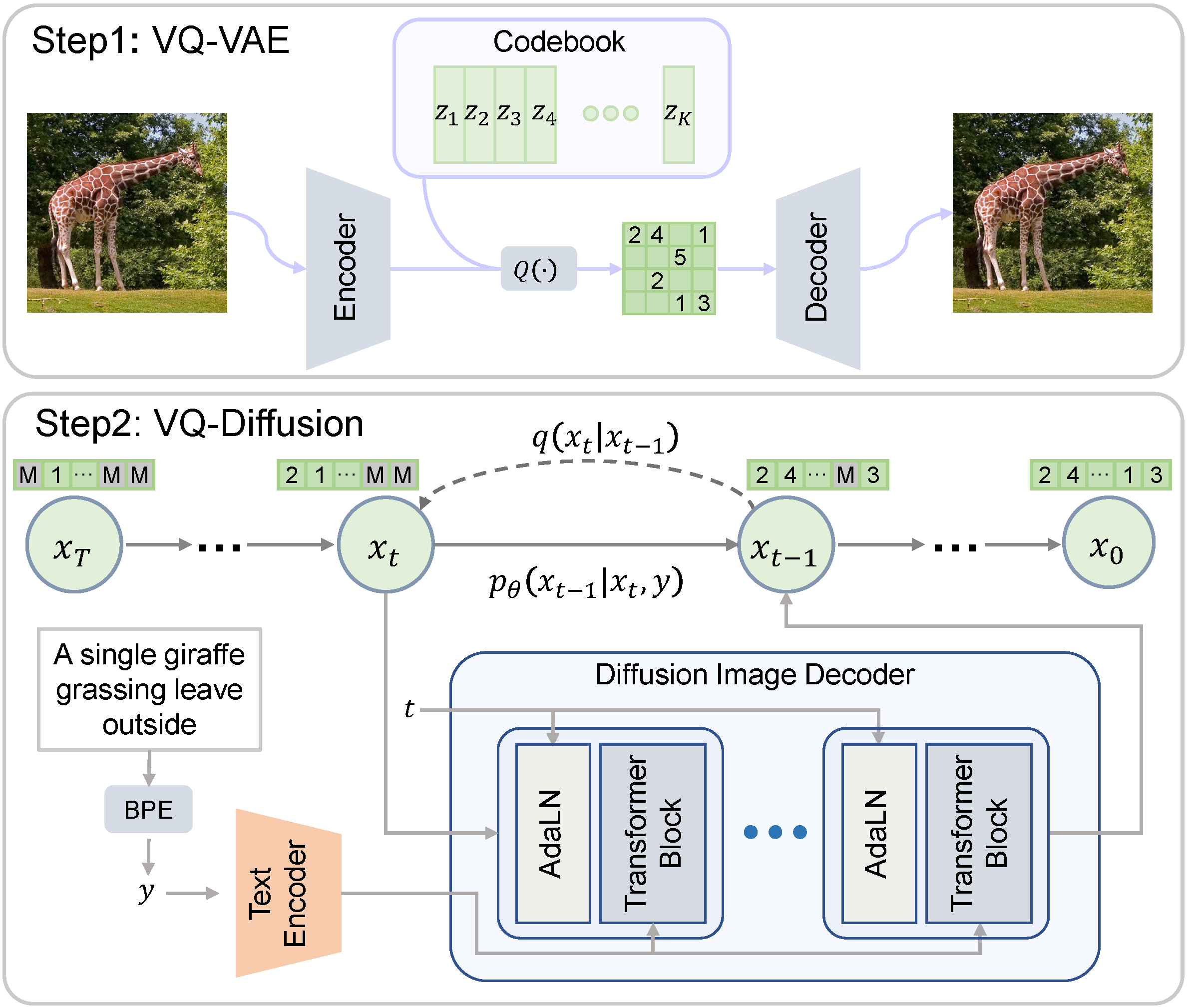
VQ-Diffusionは、拡散モデルとVQ-VAEを組み合わせ、高解像度で高品質な画像を効率的に生成する新しい手法…

Hugging Faceがインターンシッププログラムの参加者を募集しています。

Hugging FaceがDiffusion Modelsに関するライブイベントを開催しました。

Hugging Faceが機械学習インサイト担当ディレクターの役割について解説しています。