Whisper推論を2倍高速化する投機的デコーディング
Speculative Decoding for 2x Faster Whisper Inference
記事のポイント
📰ニュース
Hugging FaceがWhisperモデルの推論速度を投機的デコーディングで2倍に向上させました。
🔍注目ポイント
小型モデルで次トークンを予測し、大型モデルで検証することで、計算量を大幅に削減します。
🔮これからどうなる
Whisperの音声認識がより高速になり、リアルタイムアプリケーションでの利用が拡大するでしょう。
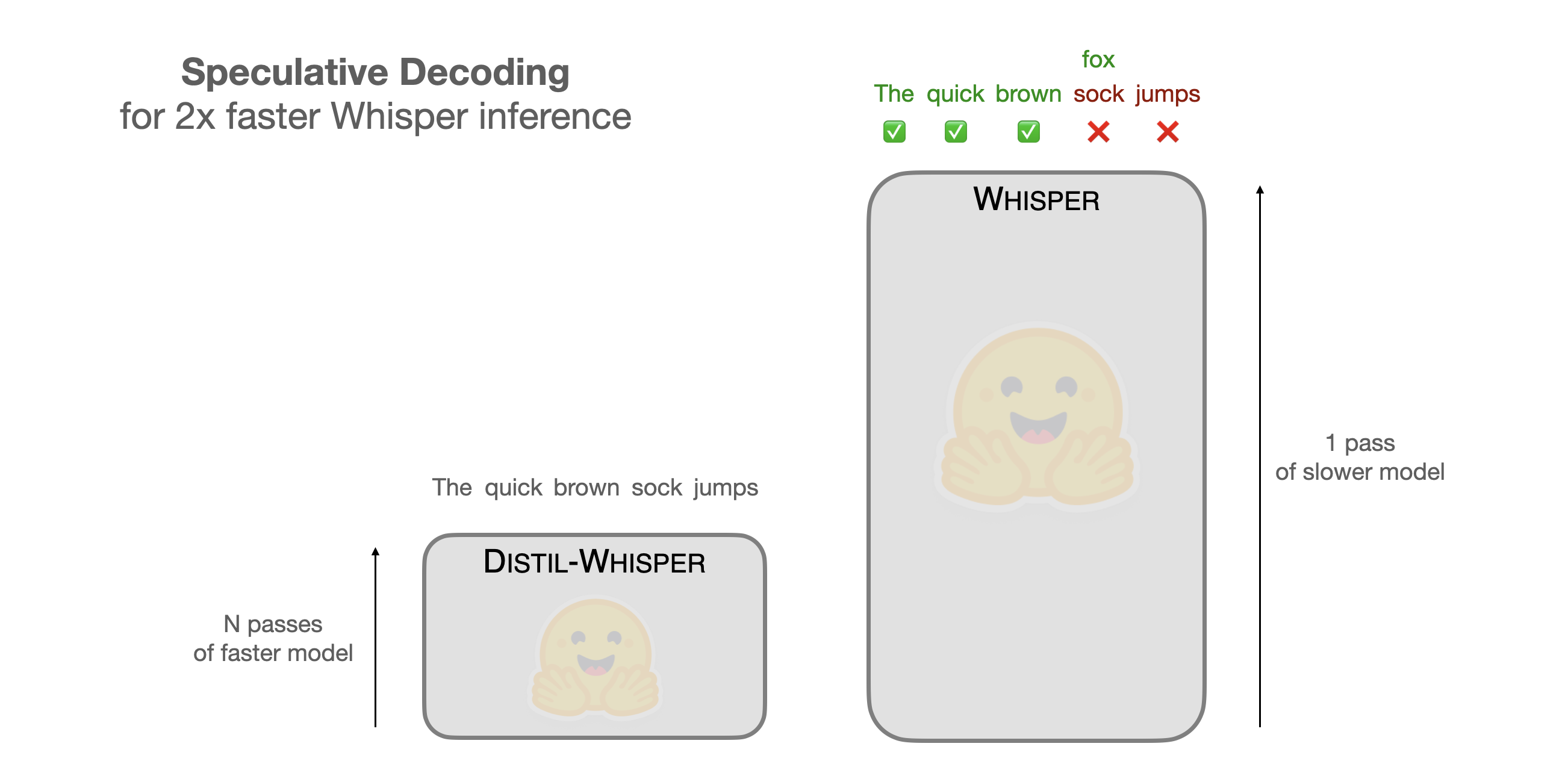
投機的デコーディングは、高速な小型モデル(ドラフトモデル)で候補シーケンスを生成し、高精度な大型モデル(ターゲットモデル)で一括検証する手法です。
これにより、大型モデルの計算を効率化し、推論時間を短縮します。
特にWhisperのようなTransformerベースのモデルで効果を発揮します。
これにより、大型モデルの計算を効率化し、推論時間を短縮します。
特にWhisperのようなTransformerベースのモデルで効果を発揮します。


Whisperがさらに速くなるのは嬉しいね!リアルタイム翻訳とか、もっと使いやすくなりそうだよ。