Mixture of Experts (MoE) 解説
Mixture of Experts Explained
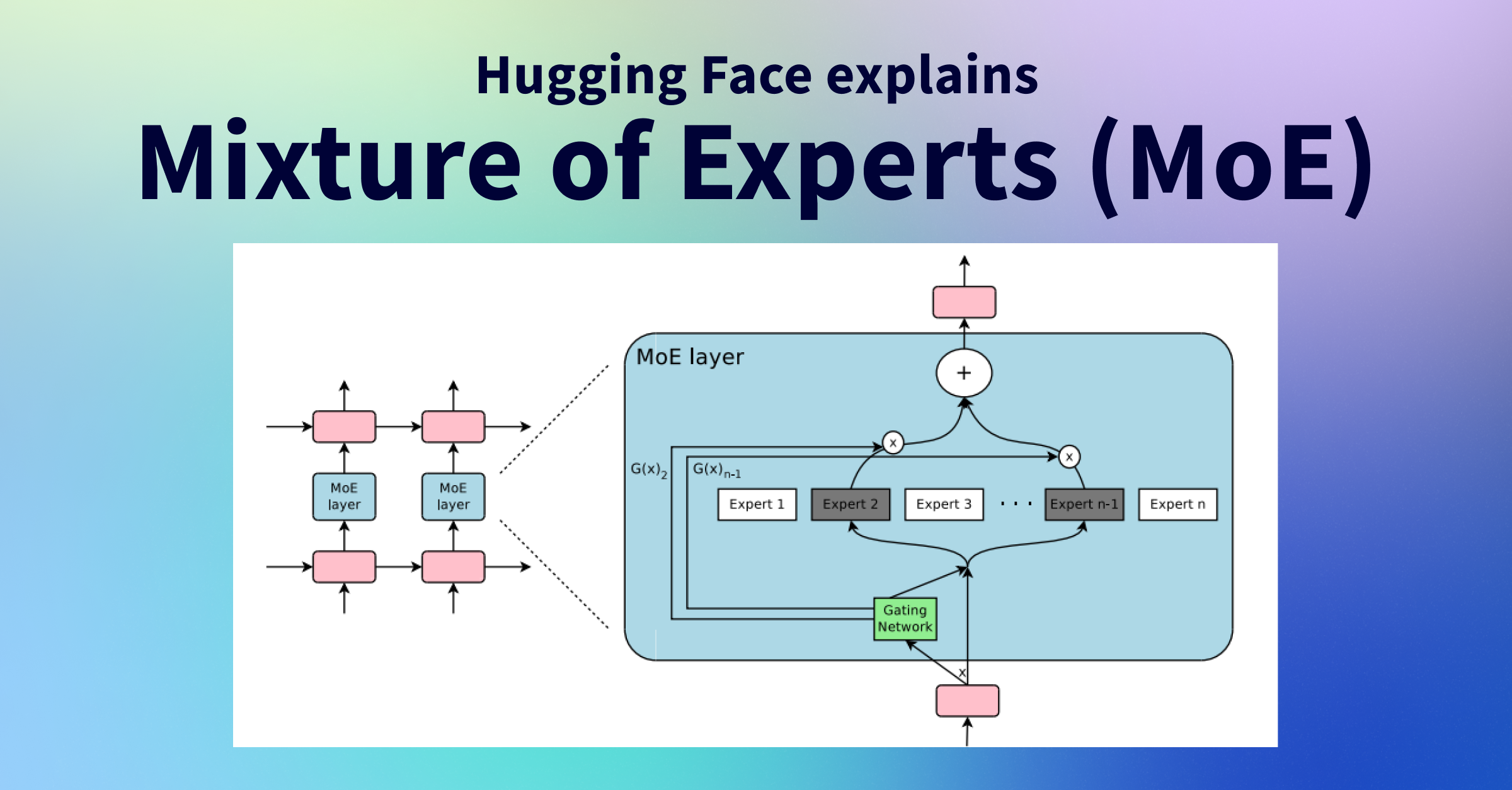
記事のポイント
📰ニュース
大規模言語モデルの効率と性能を向上させるMixture of Experts (MoE) アーキテクチャが注目されています。
🔍注目ポイント
MoEは、複数の専門家(エキスパート)ネットワークから特定の入力に最適なものを選択し、計算コストを抑えつつ高い性能を実現します。
🔮これからどうなる
より大規模で高性能なAIモデルが、より少ない計算リソースで開発・運用できるようになり、AIの普及を加速させます。
MoEは、各入力トークンに対して少数のエキスパートのみを活性化させることで、モデル全体のパラメータ数は多いものの、実際に使用される計算量は削減されます。
これにより、トレーニングと推論の効率が向上し、より大きなモデルの構築が可能になります。
特にLLMの分野で、GPT-4やMixtral 8x7Bなどで採用され、その有効性が示されています。
これにより、トレーニングと推論の効率が向上し、より大きなモデルの構築が可能になります。
特にLLMの分野で、GPT-4やMixtral 8x7Bなどで採用され、その有効性が示されています。


MoEは最近の高性能LLMでよく聞く技術だよね!計算効率を上げつつ性能も維持できるのがすごいポイントなんだ。今後のAI開発の主流になりそうだよ!