大規模言語モデルのレッドチーミング
Red-Teaming Large Language Models

記事のポイント
📰ニュース
Hugging Faceが大規模言語モデル(LLM)の安全性を評価する「レッドチーミング」について解説しました。
🔍注目ポイント
悪意あるプロンプトでLLMの脆弱性を発見し、安全なAI開発を促進する手法が紹介されています。
🔮これからどうなる
開発者はより安全で信頼性の高いLLMを構築でき、ユーザーは安心してAIを利用できるようになります。
レッドチーミングは、サイバーセキュリティ分野で使われる手法をAIに応用したものです。
攻撃者の視点からLLMの弱点(有害なコンテンツ生成、個人情報漏洩など)を探し出し、その対策を講じることで、AIの倫理的かつ責任ある利用を保証します。
Hugging Faceは、このプロセスをオープンソースコミュニティで共有し、共同でAIの安全性を高めることを目指しています。
攻撃者の視点からLLMの弱点(有害なコンテンツ生成、個人情報漏洩など)を探し出し、その対策を講じることで、AIの倫理的かつ責任ある利用を保証します。
Hugging Faceは、このプロセスをオープンソースコミュニティで共有し、共同でAIの安全性を高めることを目指しています。
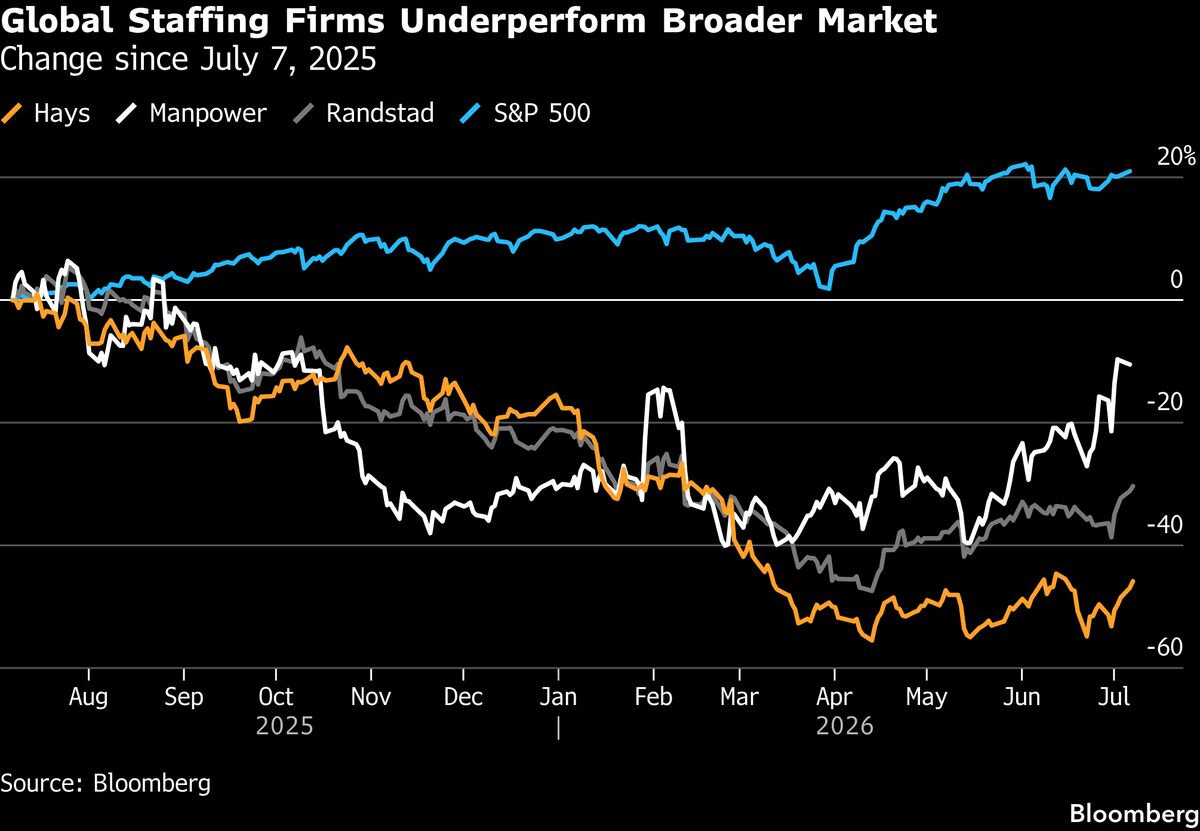

LLMの安全性って本当に大事だよね!レッドチーミングで事前にリスクを見つけておくことで、より信頼できるAIが生まれるのは嬉しいな。