BLIP-2によるゼロショット画像からテキスト生成
Zero-shot image-to-text generation with BLIP-2
記事のポイント
📰ニュース
Salesforceが開発したBLIP-2は、既存のLLMを活用し、画像からテキストを生成する能力を大幅に向上させました。
🔍注目ポイント
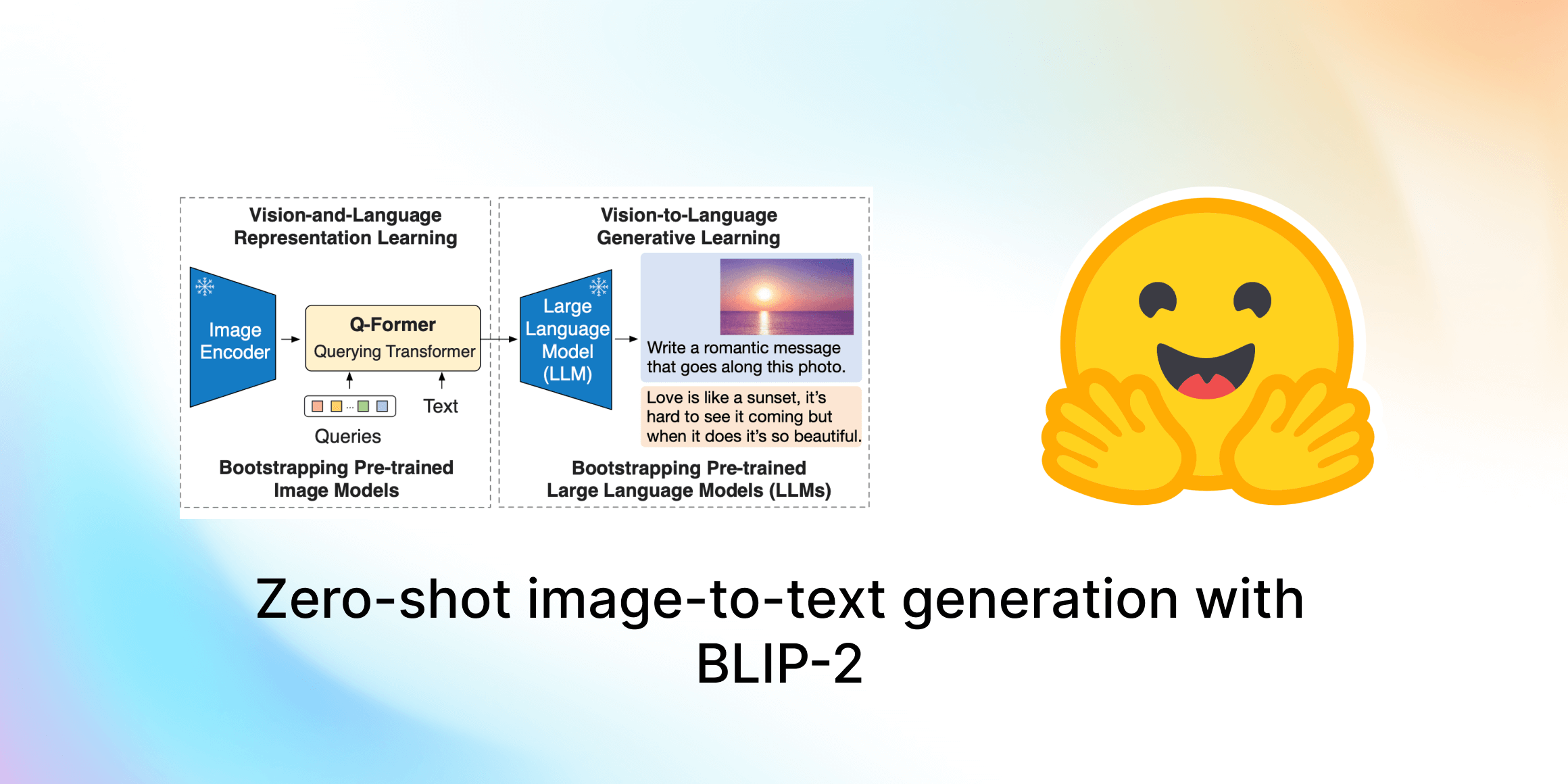
BLIP-2は、凍結された画像エンコーダと凍結されたLLMを接続するQ-Formerという軽量なモジュールを使用しています。
🔮これからどうなる
画像キャプション生成や視覚的質問応答など、多様な画像理解タスクの性能が向上し、応用範囲が広がります。
BLIP-2は、画像エンコーダとLLMを直接接続するのではなく、Q-Formerを介することで、計算コストを抑えつつ高い性能を実現しています。
これにより、既存の強力なLLMの知識を画像理解タスクに効率的に転用できるようになりました。
Hugging Face Spacesでデモが公開されており、手軽に試すことができます。
これにより、既存の強力なLLMの知識を画像理解タスクに効率的に転用できるようになりました。
Hugging Face Spacesでデモが公開されており、手軽に試すことができます。


BLIP-2は、既存のLLMをうまく活用して、画像理解の性能をぐっと引き上げたんだね!Q-Formerっていう接続モジュールが賢いなぁ。