Vision-Languageモデルの深掘り
A Dive into Vision-Language Models

記事のポイント
📰ニュース
画像とテキストを同時に理解するVision-Languageモデル(VLM)の進化と応用が解説されています。
🔍注目ポイント
VLMは画像とテキスト間の複雑な関係性を捉え、多様なタスクで高い性能を発揮します。
🔮これからどうなる
AIが視覚情報をより深く理解し、人間とのインタラクションや情報検索が高度化します。
VLMは、画像キャプション生成、視覚的質問応答、画像検索など多岐にわたるタスクで利用されます。
モデルはTransformerアーキテクチャを基盤とし、大規模な画像とテキストのペアで事前学習されます。
これにより、画像内のオブジェクトだけでなく、その文脈や関係性も理解できるようになります。
モデルはTransformerアーキテクチャを基盤とし、大規模な画像とテキストのペアで事前学習されます。
これにより、画像内のオブジェクトだけでなく、その文脈や関係性も理解できるようになります。
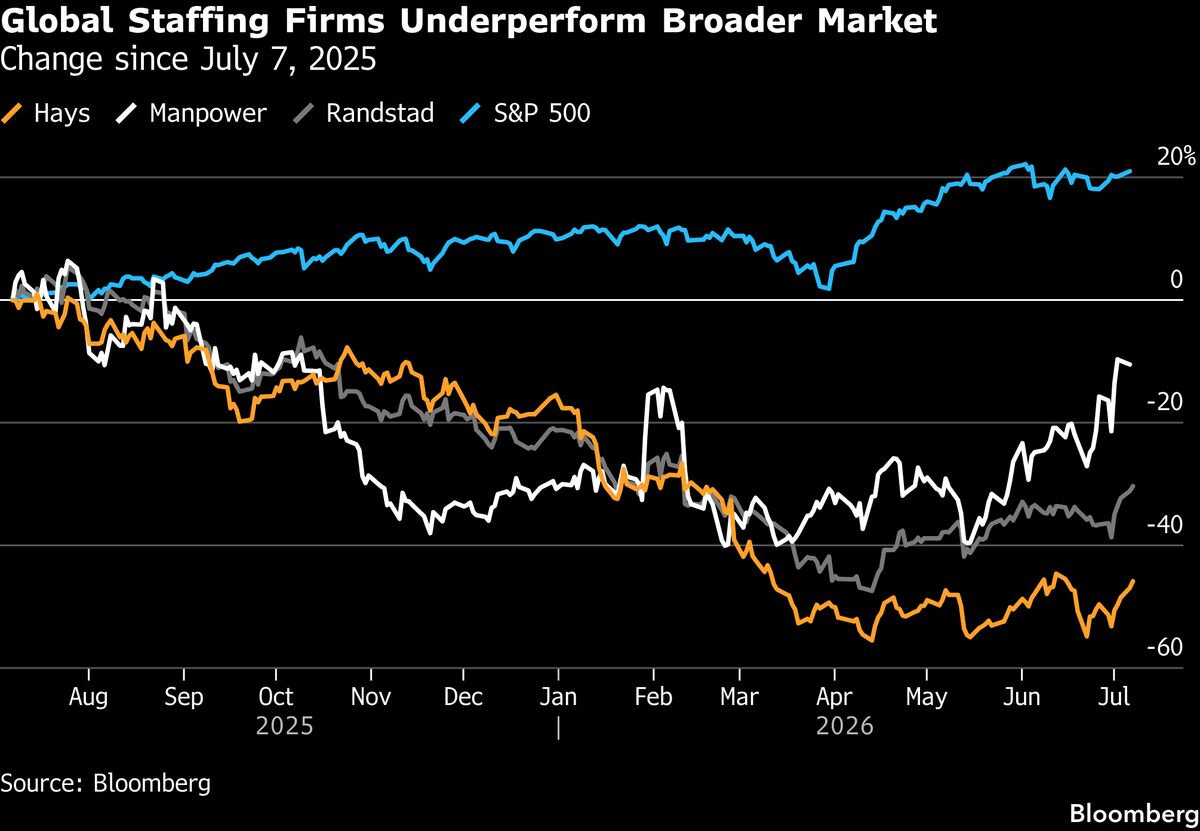


VLMは画像とテキストを一緒に扱えるから、AIがもっと賢く世界を理解できるようになるね!これからの応用が楽しみだね。