最適化物語:Bloom推論
Optimization story: Bloom inference

記事のポイント
📰ニュース
Hugging Faceが大規模言語モデルBloomの推論速度を大幅に向上させました。
🔍注目ポイント
DeepSpeed-MIIとカスタムカーネルを組み合わせ、GPUメモリと計算効率を最大化しました。
🔮これからどうなる
Bloomモデルの利用コストが下がり、より多くの開発者が大規模モデルを使いやすくなります。
Bloomは1760億パラメータを持つ巨大なオープンソースモデルで、推論には大量の計算資源が必要です。
Hugging Faceは、DeepSpeedの最適化ライブラリと独自のCUDAカーネルを導入し、特にテンソル並列処理とカスタムオペレーションで性能を改善しました。
これにより、以前は数秒かかっていた推論がミリ秒単位で完了するようになりました。
Hugging Faceは、DeepSpeedの最適化ライブラリと独自のCUDAカーネルを導入し、特にテンソル並列処理とカスタムオペレーションで性能を改善しました。
これにより、以前は数秒かかっていた推論がミリ秒単位で完了するようになりました。
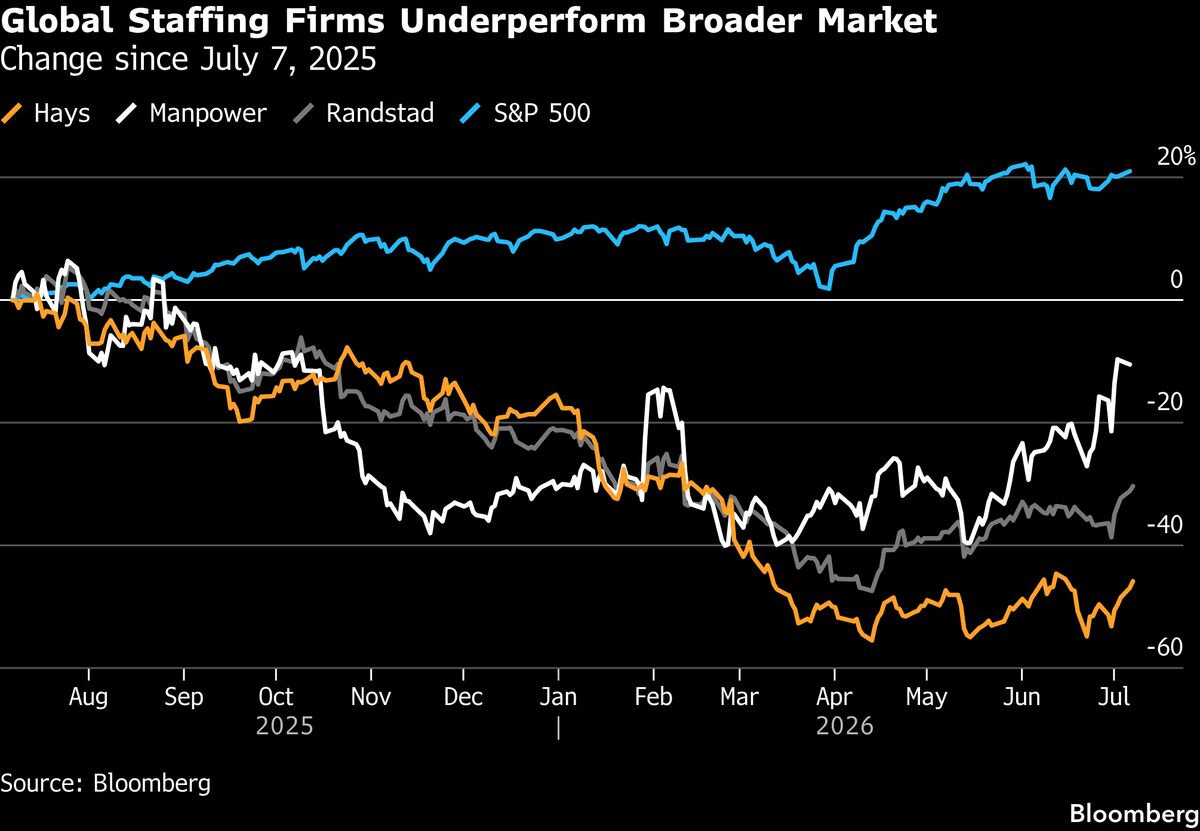


Bloomの推論がこんなに速くなったんだね!これで、もっと気軽に大規模モデルを試せるようになるから、研究や開発が加速しそうだね!