PyTorch FSDPを活用した大規模モデルトレーニングの高速化
Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel
記事のポイント
📰ニュース
PyTorchのFully Sharded Data Parallel (FSDP) を用いて、大規模モデルの学習を効率化する手法が紹介されました。
🔍注目ポイント
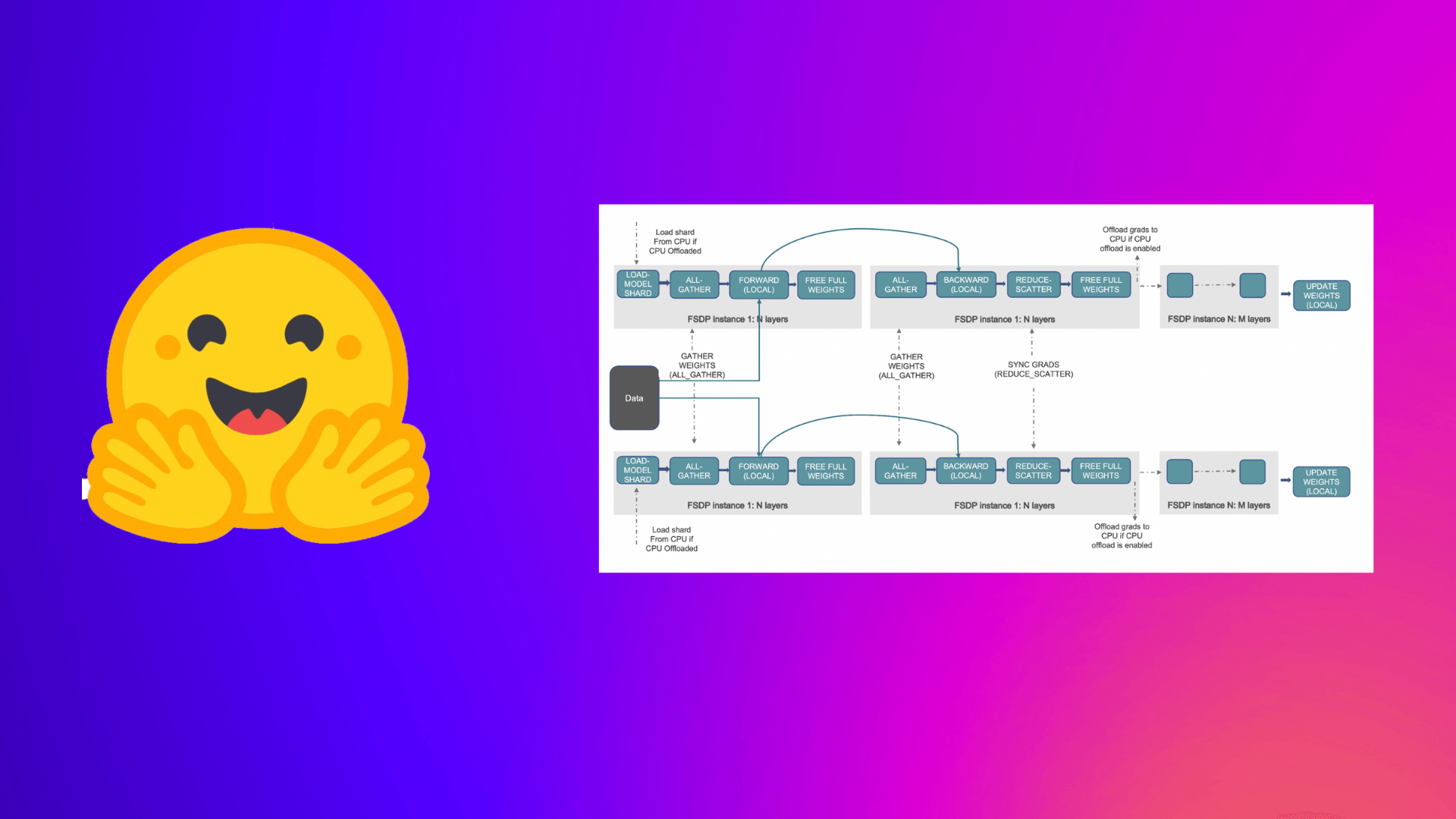
FSDPはモデルパラメータ、勾配、オプティマイザの状態をGPU間で完全にシャード化し、メモリ使用量を大幅に削減します。
🔮これからどうなる
研究者や開発者は、より大きなモデルを少ないGPUリソースで学習できるようになり、AI開発が加速します。
Hugging Face AccelerateライブラリとPyTorch FSDPを組み合わせることで、数行のコード変更で大規模モデルの分散学習を簡単に実装できます。
これにより、以前はメモリ不足で学習できなかったモデルも、より手軽に扱えるようになります。
特に、Transformerモデルのような大規模なモデルの学習に効果的です。
これにより、以前はメモリ不足で学習できなかったモデルも、より手軽に扱えるようになります。
特に、Transformerモデルのような大規模なモデルの学習に効果的です。




FSDP、やっぱり大規模モデル学習の救世主だよね!Hugging Face Accelerateと組み合わせると、本当に簡単に使えるから試してみてほしいな!