10億組の学習ペアで文章埋め込みモデルを訓練
Train a Sentence Embedding Model with 1B Training Pairs
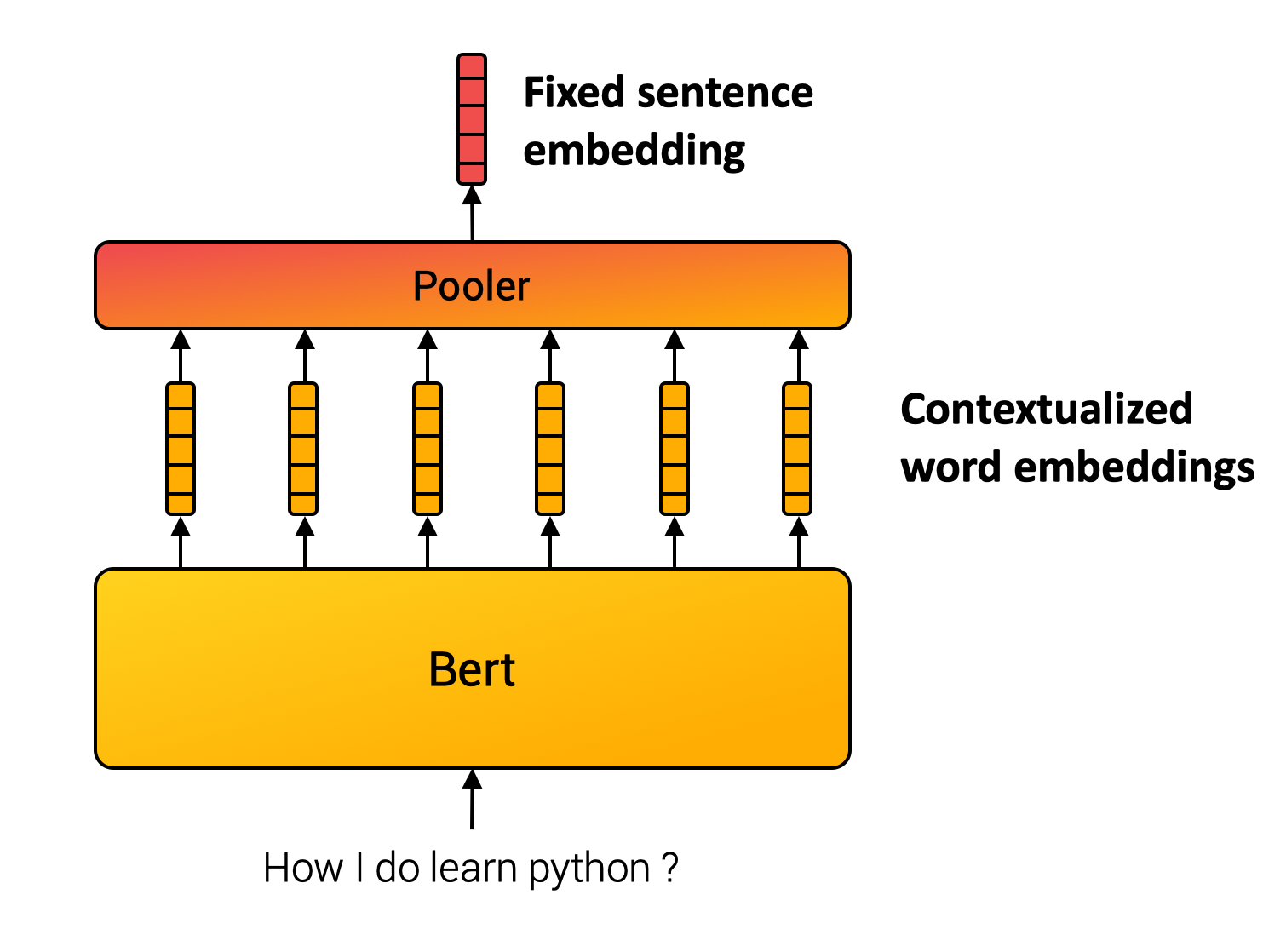
記事のポイント
📰ニュース
Hugging Faceが10億組の学習ペアを用いた大規模な文章埋め込みモデルの訓練に成功しました。
🔍注目ポイント
大規模なデータセットと効率的な学習戦略により、既存モデルを上回る高性能な埋め込みモデルを構築しました。
🔮これからどうなる
開発者はより高精度なセマンティック検索やテキスト分類をアプリケーションに組み込めるようになります。
このモデルは、異なる文脈での単語やフレーズの意味をより正確に捉えることができ、多言語対応も強化されています。
これにより、情報検索、質問応答システム、要約などのタスクにおいて、より人間らしい理解と応答が可能になります。
これにより、情報検索、質問応答システム、要約などのタスクにおいて、より人間らしい理解と応答が可能になります。



10億ペアってすごいね!これで文章の意味をより正確に捉えられるようになるから、検索とかチャットボットの精度がかなり上がりそうだね!