BigBirdのブロックスパースアテンションを理解する
Understanding BigBird's Block Sparse Attention
記事のポイント
📰ニュース
BigBirdモデルが、Transformerの二次計算量を線形に削減するブロックスパースアテンションメカニズムを採用。
🔍注目ポイント
アテンションメカニズムを工夫し、計算コストを大幅に削減しながら長文処理能力を向上させている。
🔮これからどうなる
より長いテキストを効率的に処理できるようになり、大規模言語モデルの応用範囲が広がる。
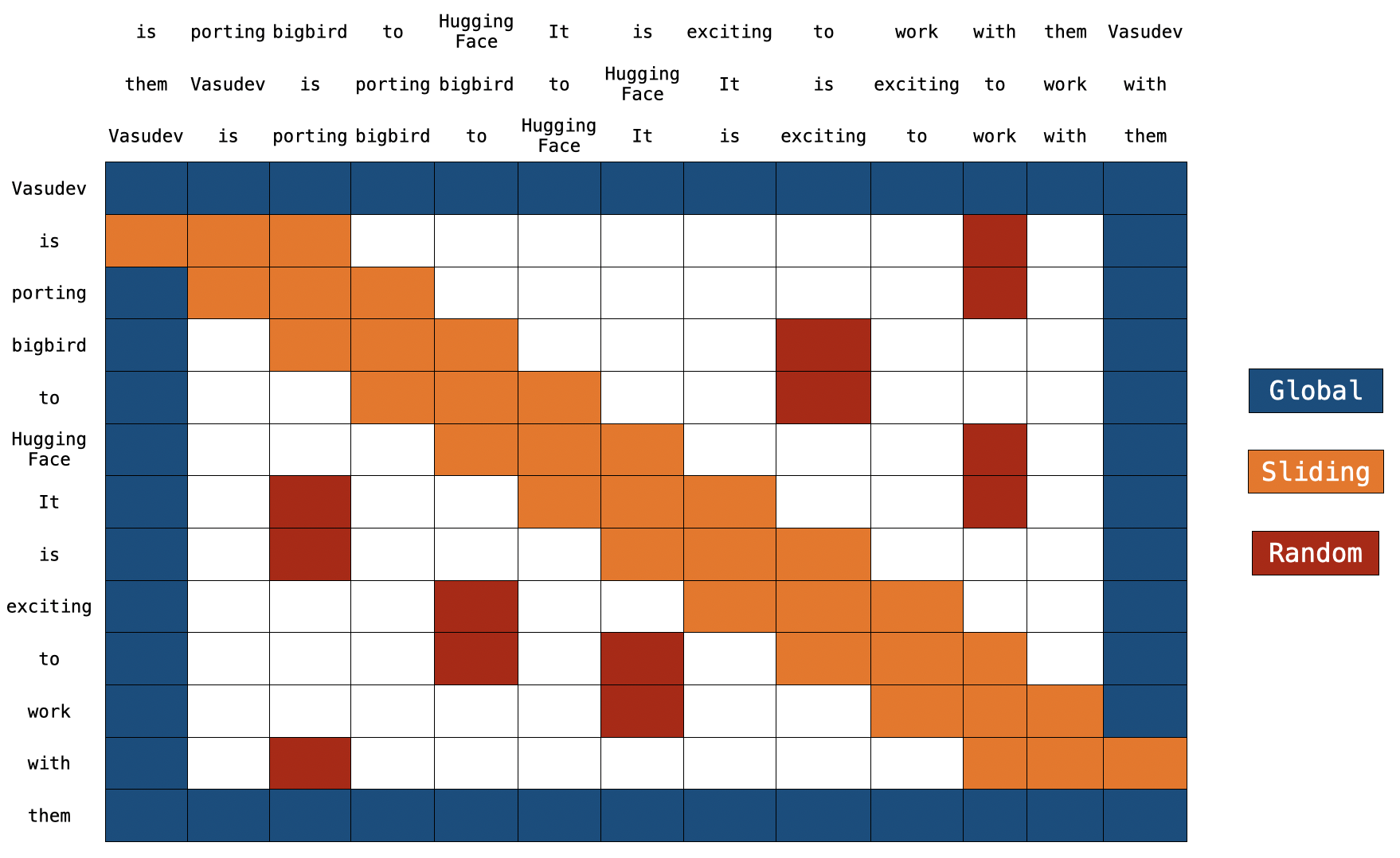
Transformerモデルはアテンションメカニズムにより高い性能を発揮するが、入力長に対して計算量が二次関数的に増加する問題があった。
BigBirdはこの問題を解決するため、全ての位置にアテンションを適用するのではなく、特定のブロックやランダムな位置にのみアテンションを適用するブロックスパースアテンションを導入。
これにより、計算量を線形に抑えつつ、長距離依存関係の学習能力を維持している。
BigBirdはこの問題を解決するため、全ての位置にアテンションを適用するのではなく、特定のブロックやランダムな位置にのみアテンションを適用するブロックスパースアテンションを導入。
これにより、計算量を線形に抑えつつ、長距離依存関係の学習能力を維持している。



BigBirdのブロックスパースアテンションは、Transformerの長文処理のボトルネックを解消する賢い方法だね。これでLLMがもっと長い文章もサクサク扱えるようになるかも!