DeepSpeedとFairScaleのZeROでより多くのモデルをより速く学習
Fit More and Train Faster With ZeRO via DeepSpeed and FairScale
記事のポイント
📰ニュース
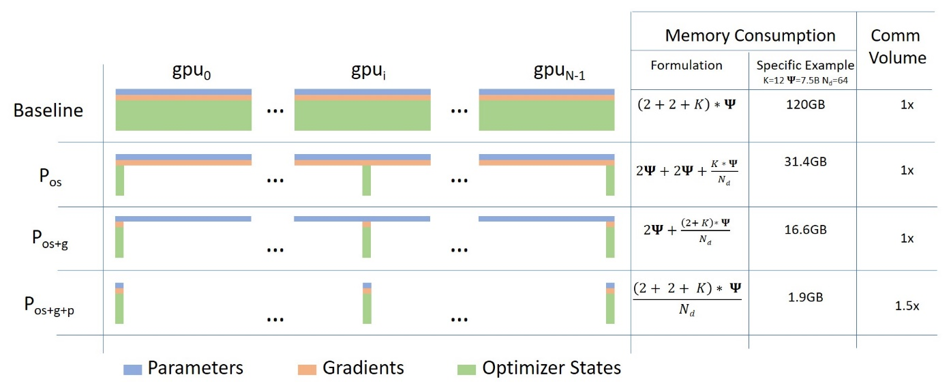
ZeRO技術を活用することで、大規模モデルの学習効率とメモリ使用量を大幅に改善しました。
🔍注目ポイント
ZeROはモデルのパラメータ、勾配、最適化状態を分散させ、GPUメモリを効率的に利用します。
🔮これからどうなる
研究者や開発者は、より大きなモデルを少ないリソースで、より速く学習できるようになります。
ZeRO (Zero Redundancy Optimizer) は、DeepSpeedとFairScaleといったライブラリで実装されている最適化技術です。
モデルの学習に必要なメモリを削減し、より大きなモデルを単一または複数のGPUで学習可能にします。
これにより、大規模言語モデルなどの開発が加速されます。
モデルの学習に必要なメモリを削減し、より大きなモデルを単一または複数のGPUで学習可能にします。
これにより、大規模言語モデルなどの開発が加速されます。



ZeROは大規模モデルの学習に欠かせない技術だよね!メモリ効率が上がるから、もっと複雑なモデルも試せるようになるのが嬉しいな。