報酬モデルの過剰最適化に関するスケーリング則
Scaling laws for reward model overoptimization
記事のポイント
📰ニュース
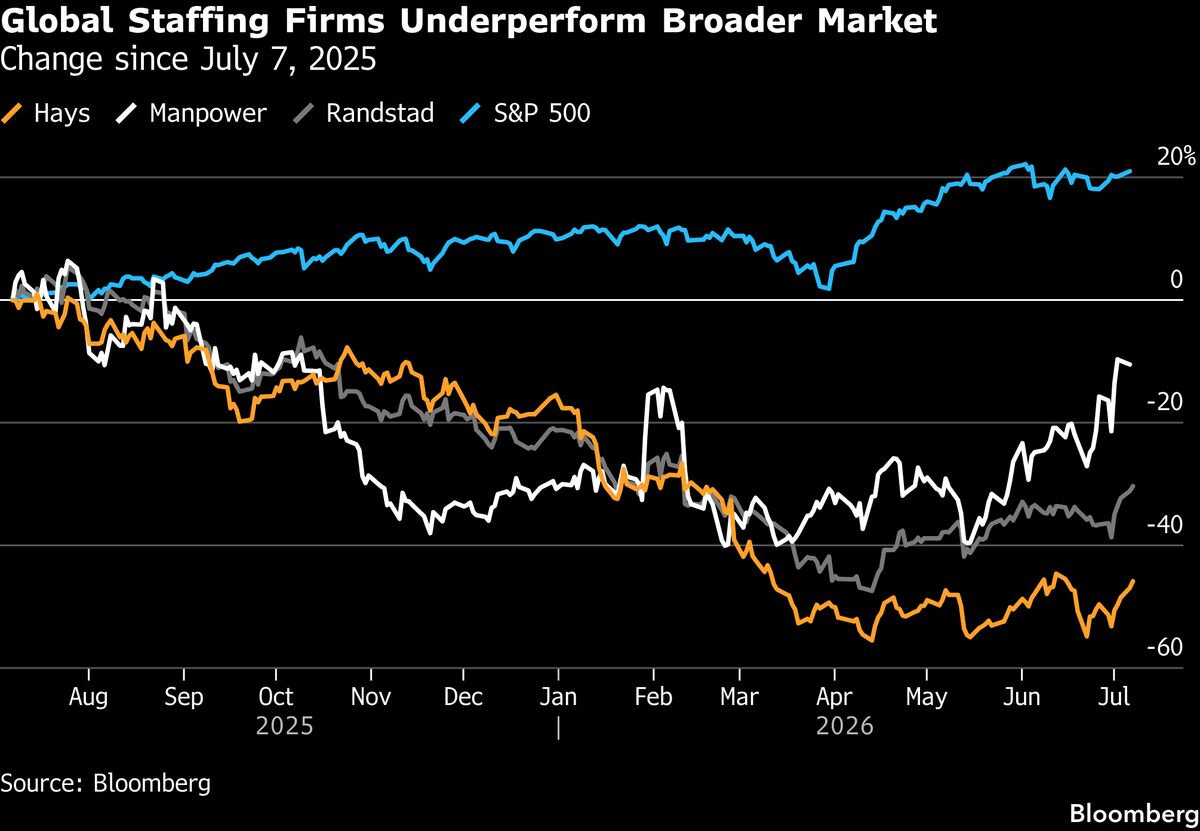
OpenAIが報酬モデルの過剰最適化が性能を低下させる現象と、そのスケーリング則を発見しました。
🔍注目ポイント
報酬モデルの容量を大きくしすぎると、モデルが報酬関数を過学習し、実際のタスク性能が低下します。
🔮これからどうなる
RLHFを用いたAIモデルの訓練において、報酬モデルの適切なサイズ選定がより重要になります。
強化学習における人間のフィードバック(RLHF)は、AIモデルの性能向上に不可欠ですが、報酬モデルの容量を大きくしすぎると、モデルが報酬関数を過学習し、実際のタスク性能が低下することが判明しました。
この現象は「報酬モデルの過剰最適化」と呼ばれ、モデルの容量とデータ量に応じたスケーリング則が存在します。
この研究は、RLHFの訓練プロセスを最適化するための重要な知見を提供します。
この現象は「報酬モデルの過剰最適化」と呼ばれ、モデルの容量とデータ量に応じたスケーリング則が存在します。
この研究は、RLHFの訓練プロセスを最適化するための重要な知見を提供します。


報酬モデルの容量を闇雲に増やせばいいってもんじゃないんだね。過学習はどこでも起きるんだなぁ。