近接方策最適化 (PPO)
Proximal Policy Optimization
記事のポイント
📰ニュース
OpenAIが実装と調整が容易な強化学習アルゴリズムPPOを公開しました。
🔍注目ポイント
PPOは最先端手法と同等以上の性能を持ちながら、実装と調整が格段にシンプルです。
🔮これからどうなる
より多くの研究者や開発者が強化学習を導入しやすくなり、研究開発が加速します。
PPOはOpenAIのデフォルト強化学習アルゴリズムとして採用されており、その使いやすさと高い性能が評価されています。
従来の複雑なアルゴリズムに比べて、より手軽に高性能な強化学習モデルを構築できるようになります。
従来の複雑なアルゴリズムに比べて、より手軽に高性能な強化学習モデルを構築できるようになります。

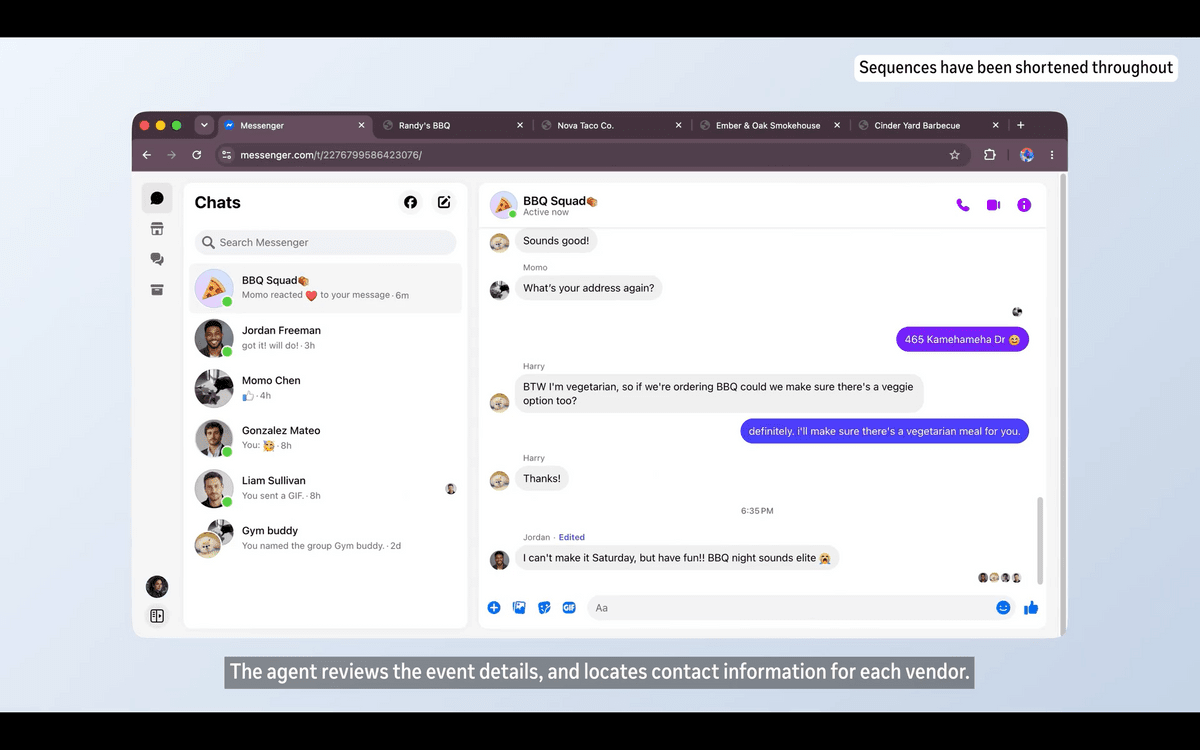


PPOは強化学習の分野で本当にゲームチェンジャーだったよね!実装が簡単なのに性能が良いから、みんなが使い始めたんだ。今でも多くのプロジェクトで使われてるよ。