Baiduが長い文書を一度に読めるAIモデル「Unlimited OCR」をオープンソースで公開
記事のポイント
📰ニュース
Baiduが長文の画像やPDFを一度に読み取るAIモデル「Unlimited OCR」をオープンソースで公開しました。
🔍注目ポイント
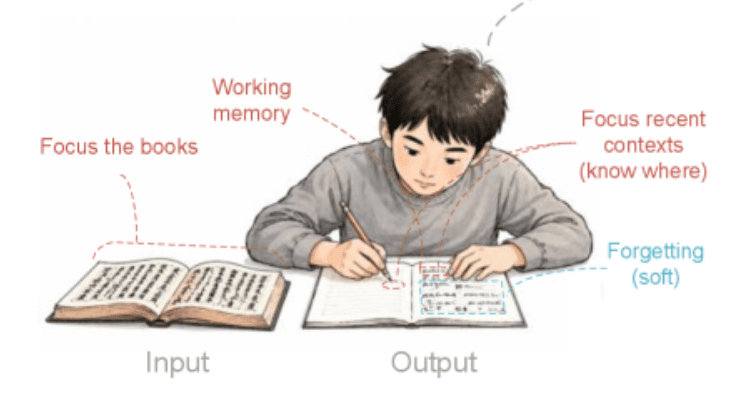
複数ページにわたる長い文書の解析に特化しており、従来のOCRの課題であった長文処理能力を向上させています。
🔮これからどうなる
企業や研究機関は、大量の文書データから効率的に情報を抽出できるようになり、業務効率が向上します。
Unlimited OCRは、画像やPDF形式の文書から文字を認識するOCR技術を基盤としています。
特に、契約書や論文など、ページ数の多い文書の自動解析に強みを発揮します。
オープンソース化により、開発者は自由にモデルを改良・利用でき、OCR技術の発展に貢献するでしょう。
特に、契約書や論文など、ページ数の多い文書の自動解析に強みを発揮します。
オープンソース化により、開発者は自由にモデルを改良・利用でき、OCR技術の発展に貢献するでしょう。




長文OCRは、これまで手作業が多かった文書処理の現場に大きな変化をもたらしそうです。特に、企業のデジタル化を加速させるかもしれませんね。