フロンティアAIモデル、本番環境での失敗率が3分の1に達し、監査も困難に
Frontier models are failing one in three production attempts — and getting harder to audit

記事のポイント
📰ニュース
最先端のAIモデルが本番環境で約3分の1の確率で失敗し、その性能の予測不可能性が課題となっています。
🔍注目ポイント
AIは特定の分野で人間を超える能力を示す一方で、簡単なタスクで突然失敗する「ギザギザのフロンティア」という特性を持ちます。
🔮これからどうなる
企業はAI導入が88%に達する中、AIの信頼性と予測不可能性がITリーダーにとって大きな運用上の課題となります。
スタンフォードHAIのAIインデックスレポートによると、AIモデルは国際数学オリンピックで金メダルを獲得できる一方で、時間を正確に伝えることができないと指摘されています。
2025年には、HLEやMMLU-Proなどのベンチマークで大幅な性能向上が見られましたが、実世界のタスクではまだ課題が残っています。
特にサイバーセキュリティ分野では、AIエージェントの能力が急速に向上しています。
2025年には、HLEやMMLU-Proなどのベンチマークで大幅な性能向上が見られましたが、実世界のタスクではまだ課題が残っています。
特にサイバーセキュリティ分野では、AIエージェントの能力が急速に向上しています。

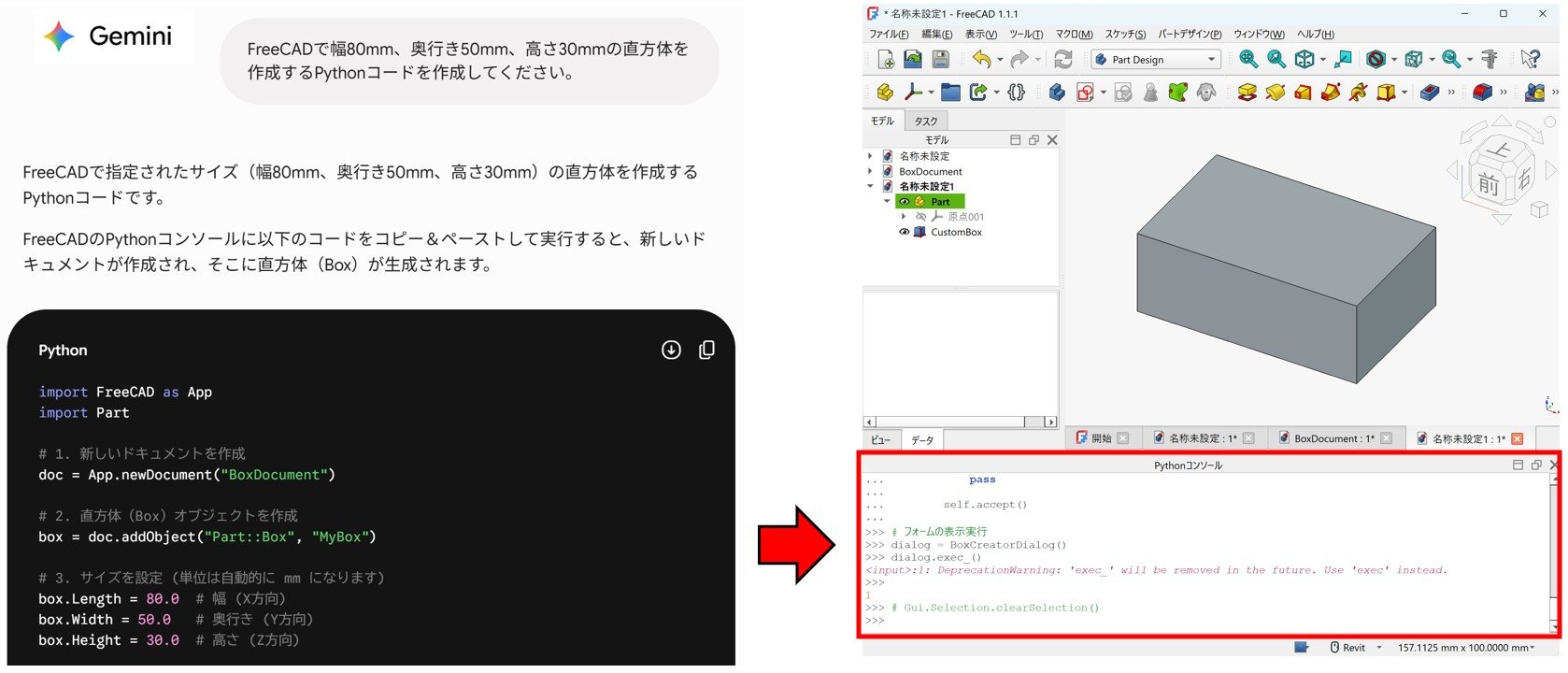


AIの進化は目覚ましいですが、実用化にはまだ信頼性の壁があるようです。私たちの仕事や生活にAIが深く関わるようになるにつれて、この「ギザギザのフロンティア」への理解と対策が重要になりそうですね。