
マイクロソフト、Buildカンファレンスで新AIモデルとWindowsの改善を発表へ
マイクロソフトがBuildカンファレンスで新たなAIモデルとWindowsの機能改善を発表する予定です。
マイクロソフトがBuildカンファレンスで新たなAIモデルとWindowsの機能改善を発表する予定です。

企業におけるAIの本格的な導入には、LLMだけでなくエージェントロジックが不可欠であると提唱されています…
中国のAI企業MiniMaxが、高性能なオープンウェイトモデル「M3」を発表しました。
Nvidiaの新しいオープンAIモデル「Nemotron 3 Ultra」が、米国製オープンモデルの中で最高性能を記録しま…

OpenAIのAIモデルが、80年間人間を悩ませてきた有名な数学問題を解決しました。
OpenAIの最先端モデルとCodexがAWS上で一般提供を開始しました。
ドイツ銀行が、現在の株式市場の主要な物語はAIであり、地政学的リスクではないと発表しました。
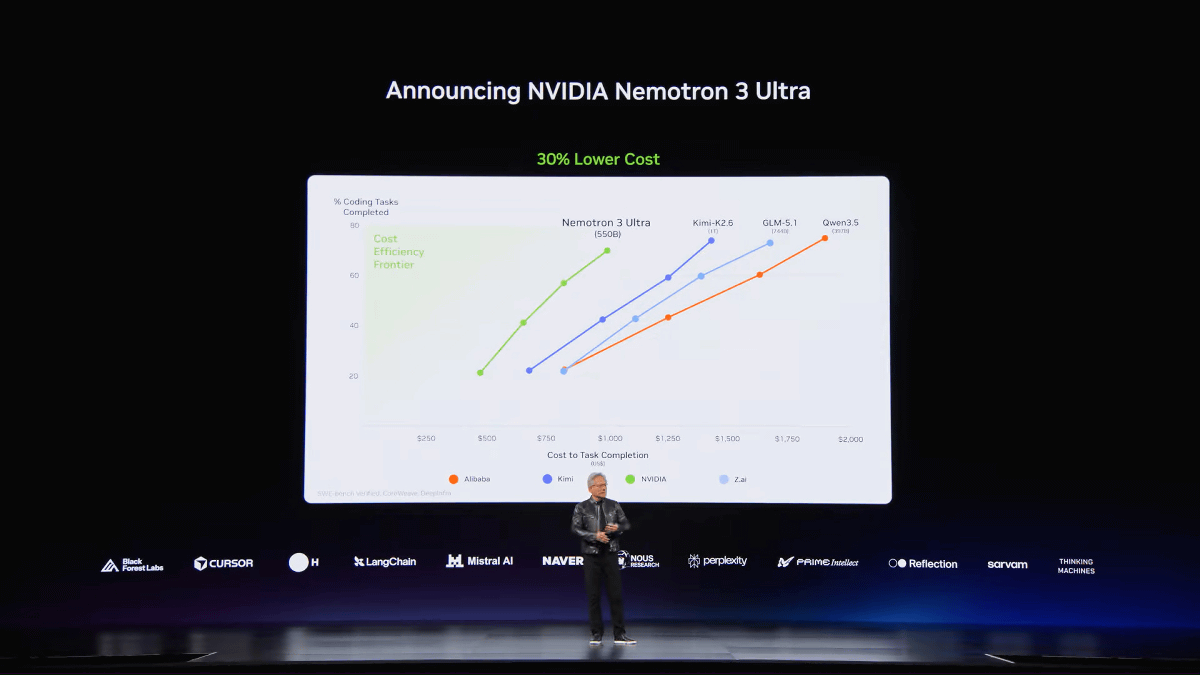
NVIDIAがアメリカ最強のオープンモデル「Nemotron 3 Ultra」とAIサーバー「Vera Rubin」の量産開始を発表…

NvidiaのCEOが、ソフトウェア関連企業の株価が市場で過小評価されていると発言しました。

NVIDIAがGB200を搭載し、最大748GBメモリを持つWindowsデスクトップPC「DGX Station」を発表しました。
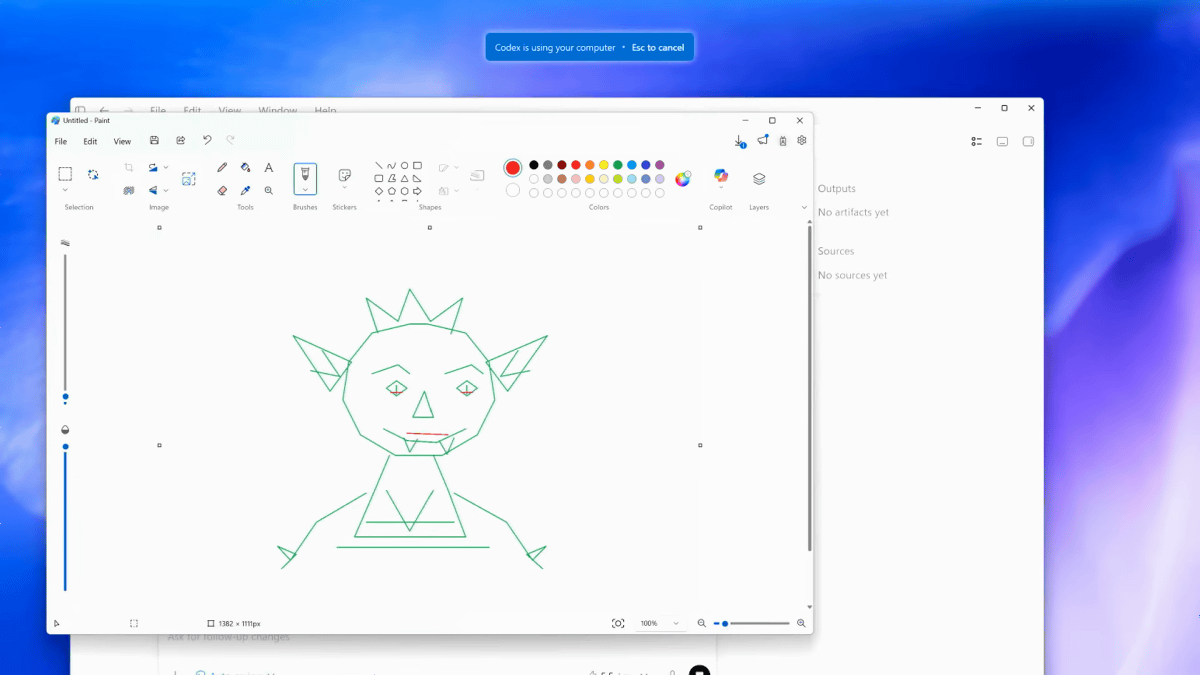
OpenAIのコーディングエージェントCodexがWindowsの自動操作に対応しました。

AIエージェントの活用が、アプリ操作の意識を不要にし、生産性に大きな差を生むと指摘されています。