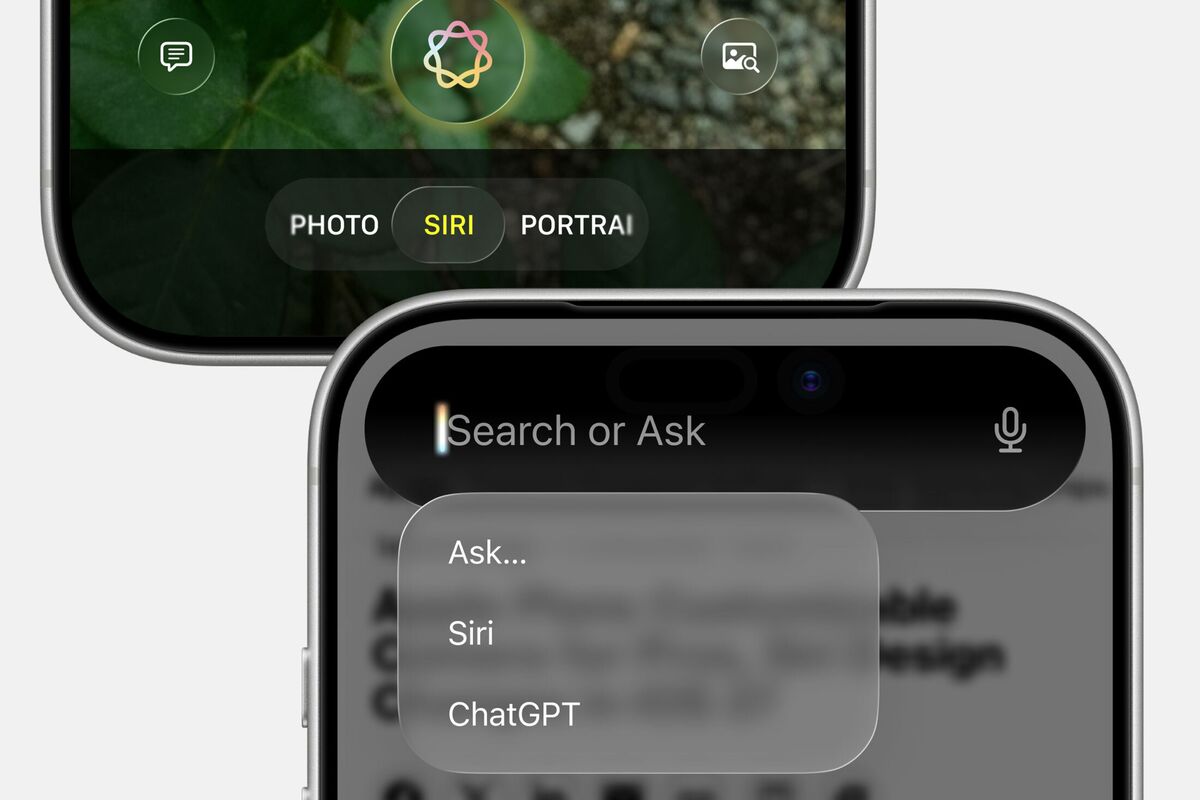
Apple、iOS 27でSiri刷新とAI機能のプレビュー画像を公開
AppleがiOS 27におけるSiriの大幅な刷新と新たなAI機能のプレビュー画像を公開しました。
AppleがiOS 27におけるSiriの大幅な刷新と新たなAI機能のプレビュー画像を公開しました。

AIエージェントの「記憶」が人間の記憶とどう異なるかについて、エンジニアが解説しました。
EndavaがOpenAIのCodexを利用し、ソフトウェア開発を加速するエージェント型組織を構築しました。
OpenAIがリアルタイム音声AIの開発で、応答内容以外の要素が重要だと発表しました。

MetaがAIチャットボットからの収益化としてサブスクリプションモデルを検討しています。
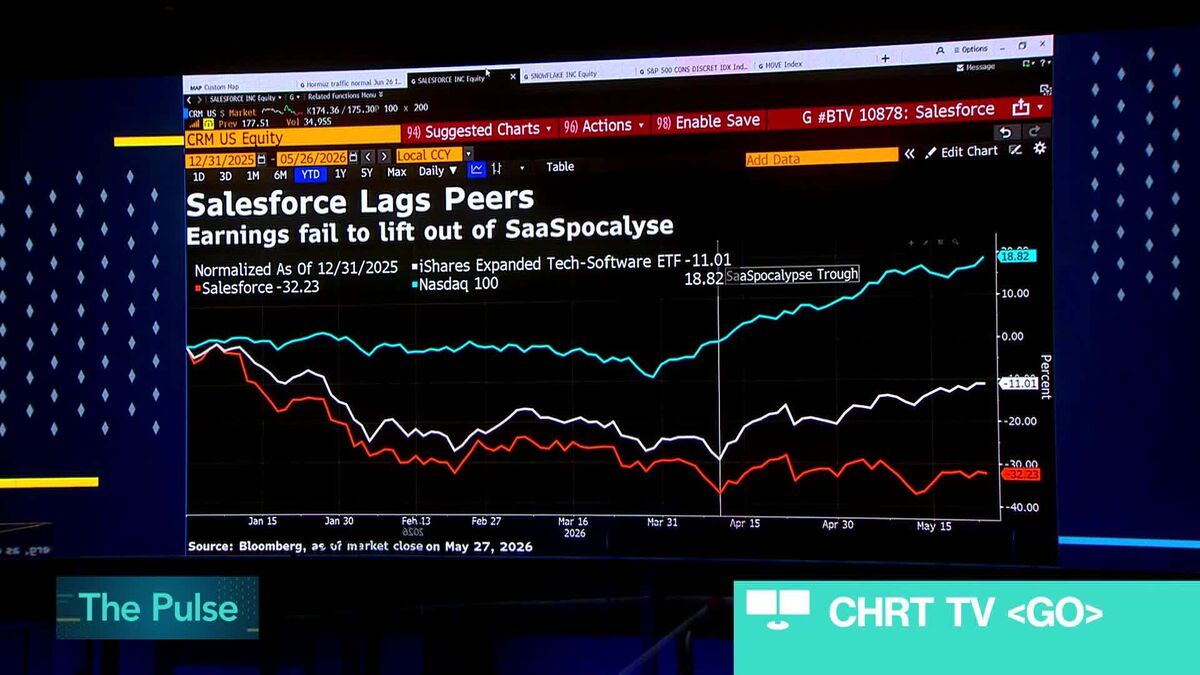
セールスフォースが発表した今期の売上高見通しがアナリスト予想を下回った。

YouTubeがAIを活用し、ユーザーの要望に応じたパーソナライズされた動画フィードを生成する新機能を発表し…

米アマゾンがAI生成技術を活用したアニメシリーズ3作品の制作を発表し、Amazonプライムビデオで配信予定で…

OpenAIが選挙対策を強化し、ChatGPTにAP通信の開票データを導入します。

Amazon MGMスタジオがAI活用映像制作支援ファンドとAI制作プラットフォームを発表しました。

アフリカのスタートアップが、米国AIブームによるベンチャーキャピタル(VC)の米国集中を受け、資金調達…

ElevenLabsが1曲内で自然にジャンルを切り替えられる音楽生成AI「Music v2」をリリースしました。