
アンドリーセン・ホロウィッツが出資するAI検索スタートアップExa、22億ドルの評価額に
AI時代に特化した検索エンジンを目指すExa Labsが、2.2億ドルの評価額で2.5億ドルを調達しました。
AI時代に特化した検索エンジンを目指すExa Labsが、2.2億ドルの評価額で2.5億ドルを調達しました。

主要なチャットボットが、選挙やニュース関連の質問に対して不正確な回答を返すことが調査で明らかになり…

Googleの新型AIモデルGemini 3.5 Flashは、性能向上と引き換えに運用コストが大幅に上昇しました。

Hacker NewsユーザーがGoogleのGemini 3.5 Flashの総パラメータ数を2500億~3000億と推定しました。
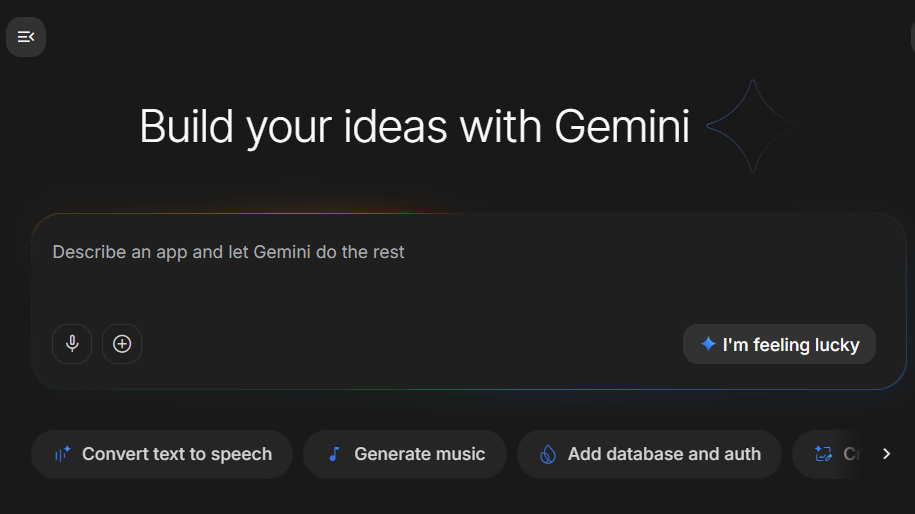
Google AI Studioに、自然言語でAndroidアプリを生成する機能が追加されました。

Googleが映画制作ツール「Flow」と音楽制作ツール「Flow Music」をGemini Omni搭載で大幅アップデートしま…

Googleが新AIモデル「Gemini 3.5」やAI検索強化などを発表し、OpenAIへの対抗姿勢を鮮明にしました。
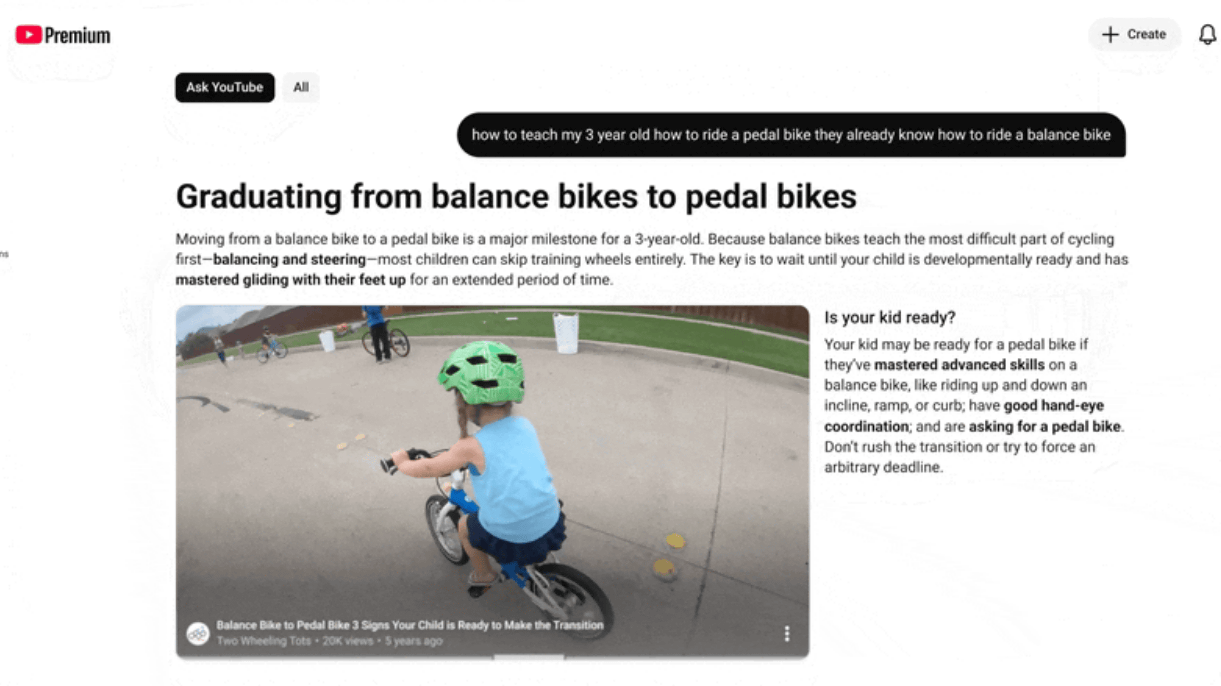
YouTubeが対話型検索「Ask YouTube」と、Gemini Omniによるショート動画リミックス機能を発表しました。

Googleが科学研究を支援するAI機能コレクション「Gemini for Science」を発表しました。
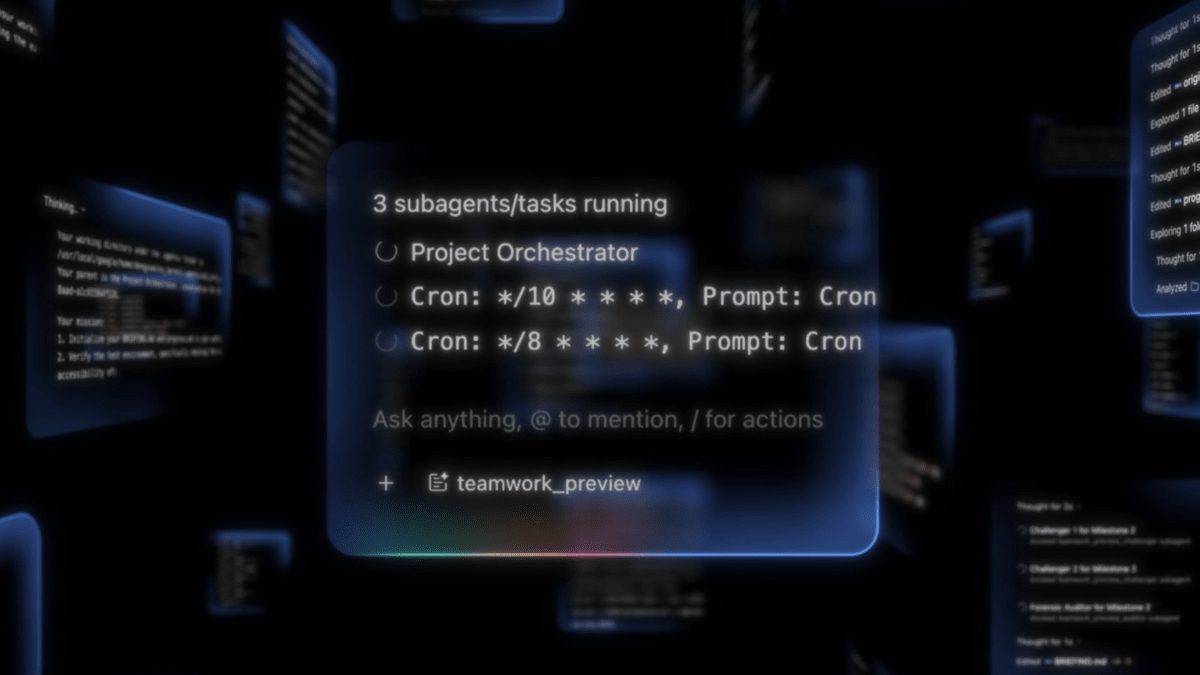
GoogleがGemini APIに「マネージドエージェント」を追加し、AIエージェントの実行環境を提供開始しました。

Googleが24時間365日稼働するAIエージェントプラットフォーム「Gemini Spark」を発表しました。

GoogleのAI開発ツール「Antigravity」がAndroidアプリ開発に正式対応しました。