
WWW発明者ティム・バーナーズ=リー氏、AI開発を語る
WWWの発明者ティム・バーナーズ=リー氏が、AIの発展について見解を述べました。
AI&Tech、もう追いかけなくていい。
30秒で読めるニュースダイジェスト
WWWの発明者ティム・バーナーズ=リー氏が、AIの発展について見解を述べました。

スマートフォンによる注意散漫の課題に対し、ユーザーの集中力回復を支援する「スローテック」製品が注目…

バーニー・サンダース上院議員がAI産業の管理権を国民に与える7兆ドルの計画を提案しました。
OpenAIがChatGPT Enterprise向けに、利用状況分析と支出管理機能を新たに導入しました。

Googleドキュメントに表示される「Geminiで書く」などのAI提案を無効にする方法が紹介されました。

『クィア・アイ』のライフコーチ、カラモ・ブラウンが自身のAIデジタルクローンを搭載したウェルネスアプ…

アンデュリル社が米空軍の自律型戦闘機の製造契約とソフトウェア提供における主要な役割を獲得しました。

トランプ前大統領が、インテルがアップルと国内での半導体設計・生産で協力すると発言し、インテル株が急…

Amazon従業員が、シアトル市議会でデータセンター制限を支持する証言をした後、報復として解雇の危機に瀕…
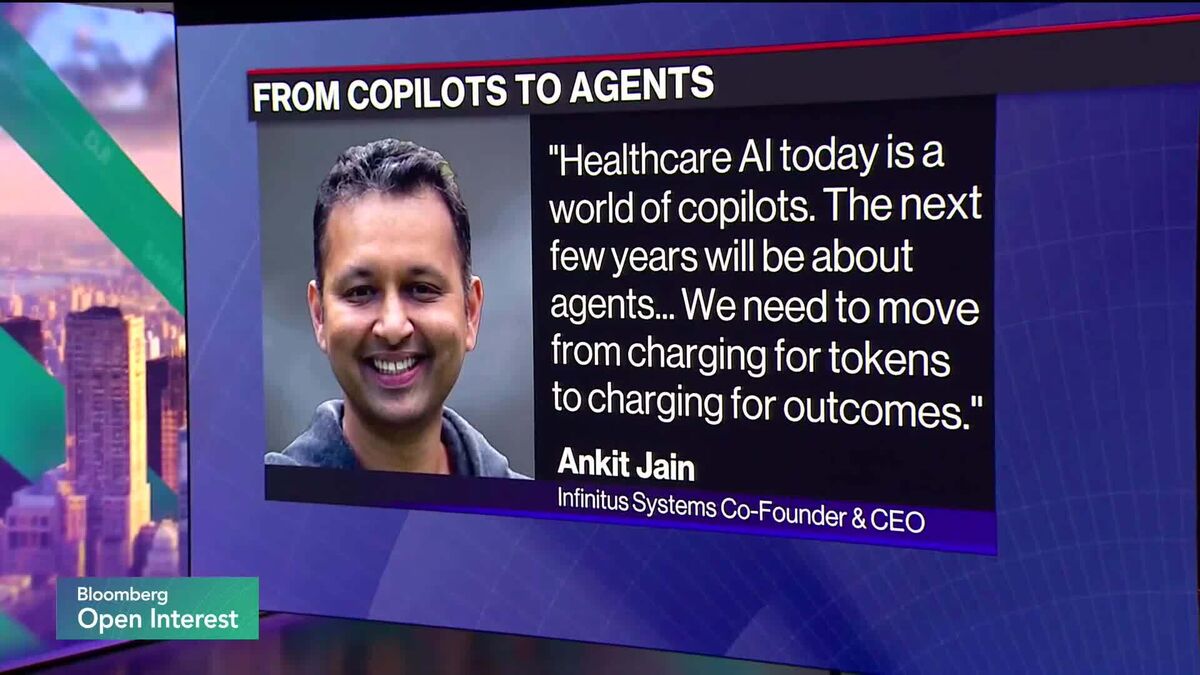
InfinitusのCEOが、ヘルスケア分野でAIが自律型エージェントとしてタスクを完遂する未来を語りました。

AIエージェント開発のGeneral Intuitionが、約20億ドルの評価額で3億ドルの資金調達を交渉中です。

テック労働者が支援する政治活動委員会(PAC)「Guardrails」が、AI業界の政治献金競争に500万ドルで参戦…